
项目名称
花朵分类任务
项目内容
提供6000张左右的102类花朵图片作为训练集,让机器学会将测试集的花朵图片正确分到102类中。
实现过程(只贴重要步骤)
导入数据库
其实当时我也并不是一下子确定用什么库,实际上我是边写边加。
import torch
import cv2
import os
import numpy as np
import torch.utils.data as data_utilstorch:基本的深度学习库。
cv2:这是我相对于原b站视频的一个自我尝试,我试图用学过的opencv知识读取本地图片。
os,numpy:python基本库,读取文件+数据处理。opencv读取图片后存取的数据类型时numpy数组。
torch.utils.data:可用Adam
数据处理(opencv)
root_dir = 'D:\\CNNTry\\flower_data\\train'
folder_dir = r"D:\CNNTry\flower_data\valid"
img_ext = ('.png', '.jpg', '.jpeg', '.bmp', '.gif')
target_size = (64,64)
num_classes = 102
batch_size = 32
确定一下数据路径,训练批次,一次的训练数量。
def get_classes(root_path):
classes = [d for d in os.listdir(root_path) if os.path.isdir(os.path.join(root_path,d))]
classes.sort() class_to_idx = {cls_name: i for i,cls_name in enumerate(classes)}
return class_to_idx
class_to_idx = get_classes(root_dir)
给每个训练集数据贴上标签。
下一步是用opencv读取训练集,代码内容相对较多且不是重点,故不赘述。
# 随机水平翻转,数据增强 if np.random.rand() > 0.5: img_size = cv2.flip(img_size, 1)
通过数据水平翻转,增强样本总量,同时防止过拟合。
train_loader = data_utils.DataLoader( dataset = train_dataset, batch_size = batch_size, shuffle = True ) test_loader = data_utils.DataLoader( dataset = test_dataset, batch_size = batch_size, shuffle = True )
这部分代码的作用是构建训练集和测试集的数据加载器。DataLoader是PyTorch中用于批量读取数据的工具,它可以自动按批次加载数据集,并支持打乱数据顺序等操作,方便模型训练与测试。
train_loader:用于加载训练集数据,每次按设定批次读取,并自动打乱数据顺序,避免模型学习到数据的顺序特征。
test_loader:用于加载测试集数据,批次大小与训练集保持一致,用于模型训练后的效果评估。
通过这两个加载器,模型可以在训练和测试阶段高效、有序地读取数据,是深度学习训练流程中标准的数据读取模块。
构建CNN网络
最基本的torch.nn.Module初始化我就不说了,这里简单提一下我构造的CNN结构即可。
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(3,32,kernel_size=5,padding=2),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32,64,kernel_size = 5,padding = 2),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(64, 128, kernel_size=3, padding=1),
torch.nn.BatchNorm2d(128),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(128, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm2d(256),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.fc = torch.nn.Linear(256 * 4 * 4 , num_classes)该部分构建了卷积神经网络的特征提取结构与分类器。整体结构由四组卷积模块和一个全连接层组成,用于完成图像特征学习与分类任务。
第一组卷积模块输入三通道图像,使用 32 个 5×5 卷积核提取基础特征,通过批归一化加速训练并提升稳定性,采用 ReLU 激活函数引入非线性,最后通过 2×2 最大池化下采样,缩小特征图尺寸。
第二组卷积模块将通道数提升至 64,保持相同的卷积核与填充方式,进一步提取更深层次的特征,同时通过池化操作继续压缩特征维度。
第三、四组卷积模块将通道数依次扩展到 128 和 256,使用 3×3 卷积核提取更精细的特征,在增加通道数的同时不断压缩特征图尺寸,使网络学习到更高级的语义信息。
经过四层卷积与池化后,输出 256 通道的特征图。全连接层将特征图展平为一维向量,并映射到指定的类别数量,输出最终的分类结果。
接下来就是前向传播过程。
反向传播
loss_func = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(cnn.parameters(), lr = 0.0001 ) scheduler = torch.optim.lr_scheduler.StepLR(optimizer = optimizer, step_size = 20, gamma = 0.8 )
这部分代码定义了模型训练所需的损失函数、优化器和学习率调整策略。
使用交叉熵损失函数作为分类任务的损失计算标准,用于衡量模型输出与真实标签之间的误差。
优化器选用 Adam 算法,以 0.0001 的初始学习率更新网络中的所有可训练参数,在保证收敛速度的同时提升训练稳定性。
同时设置学习率调度器,每经过 20 个训练轮次,将当前学习率乘以 0.8 进行衰减,使模型在训练后期能够更平稳地收敛,提升最终效果。
训练+结果展示
结果如下:
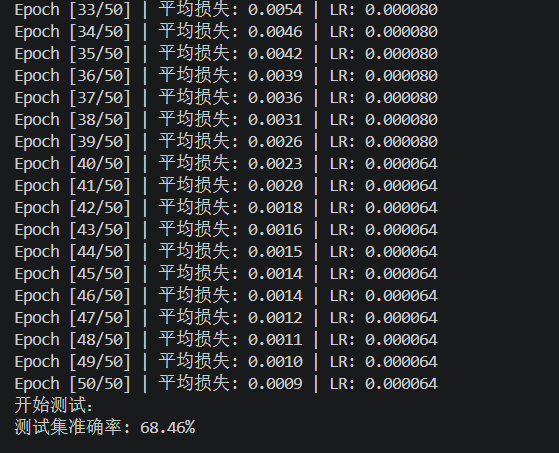
分析结果
测试机准确率和训练集准确率的差距还是挺大的。训练集准确率过高,说明有一定的过拟合;不过,鉴于102分类任务只有上千张图片,也能理解。
试图优化
通过自我查阅,询问豆包,调参尝试,我找到了一些优化方法:
# 【优化】定义全局归一化参数(ImageNet 标准均值方差,大幅提升收敛速度)
mean = np.array([0.485, 0.456, 0.406], dtype=np.float32)
std = np.array([0.229, 0.224, 0.225], dtype=np.float32)这段代码的作用是采用深度学习中标准的图像归一化优化策略,使用 ImageNet 数据集的通用均值和标准差对输入图像进行标准化处理,以此提升模型训练效果。
在数据预处理阶段,将图像像素值按照设定的均值和标准差进行归一化,使输入数据的分布更加稳定规范。采用业界通用的固定参数而非自行计算,能够让模型在训练时更快收敛,减少数值波动带来的不稳定性,同时提升卷积神经网络的特征提取效率与最终的分类精度,是图像分类任务中常用且有效的优化手段。
# 归一化 0~1
img = img.astype(np.float32) / 255.0
# 【优化】标准归一化(必须加,训练更稳)
img = (img - mean) / std通过进一步的标准归一化,使得数据在训练过程中更加稳定,不容易产生梯度爆炸,梯度消失等。
# 【优化】全连接层增加 Dropout 防止过拟合 + 隐藏层
self.fc = torch.nn.Sequential(
torch.nn.Flatten(),
torch.nn.Linear(256 * 4 * 4, 512),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Dropout(0.5), # 【优化】防止过拟合
torch.nn.Linear(512, num_classes)
)对原有全连接层进行结构优化,将单层分类结构扩展为包含隐藏层的双层网络。首先通过展平操作将卷积输出的多维特征转换为一维向量,再通过第一层全连接层将特征映射到 512 维隐藏空间,配合批量归一化和 ReLU 激活函数增强特征表达能力。在隐藏层后加入 Dropout 层,随机失活 50% 的神经元,有效降低网络神经元间的协同依赖关系,避免模型在训练过程中过度拟合训练数据。最后通过第二层全连接层输出对应类别的预测结果,在提升模型特征拟合能力的同时,保证了泛化性能。
优化后性能对比
测试时间增加许多,原测试时间约30min,新测试时间约2h20min。
结果展示:
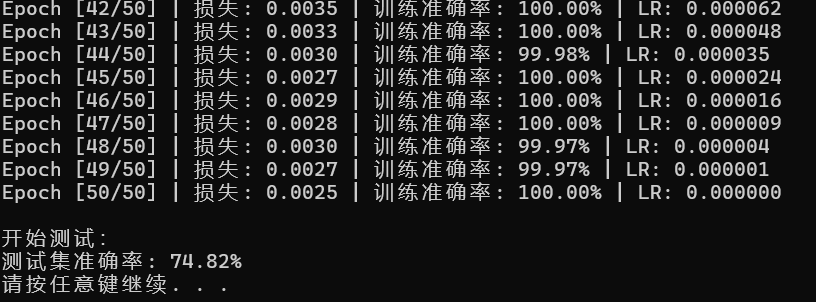
可以看到,测试集增长了不少,这说明我的优化是成功的。
结语
CNN模型的微型实验,进一步加深了我对这种卷积神经网络结构的理解,同时也能看到CNN还是有上线的,这也吸引了我去进一步的学习Transformer架构。