
虽然现在,transformer已经是NLP领域(自然语言处理领域)的一个标准了,但是用transformer来做CV还是很有限的。在视觉里,自注意力要么和卷积神经网络一起用,要么就是把一些卷积替换成自注意力。这篇文章试图证明,transformer在CV领域对于卷积神经网络的以来,是不必要的。
题目解读:
一张图片可以分割成16*16的单词(patch),用transformer去做大规模图像识别。
Transformer在视觉领域中的问题:
如何将2D图片变成1D矩阵,仍旧是个挑战。理想状态下,把2D图片构成的张量拉直成1D张量,再采用NLP中的transformer机制进行操作;但是,想法很美好,现实很骨感,一般训练任务时,输入图片的大小为224 × 224,如果把图像中每个像素点当成一个元素看待,按照上述操作,那么其序列长度会远远超过512,复杂度会非常恐怖。
现有的一些操作
1.把图片的特征图当作输入量进行Transformer操作。
2.孤立自注意力:输入不用整张图,就用一个局部的小窗口,通过控制窗口的大小降低计算复杂度。
3.轴自注意力:先在高度这个维度上进行自注意力,再在宽度这个维度上进行自注意力。
现状:硬件不支持训练加速,不如传统残差网络。
在引言中,作者提出了可以将图片拆成16*16的小图片,最多会有196个图片,这样训练就使得复杂性大大降低。然而通过实验验证,作者发现,Transformer如果能带有传统神经网络具有的Locality和Weight Sharing,或许又能大大提升训练效果。
相关工作
整体架构
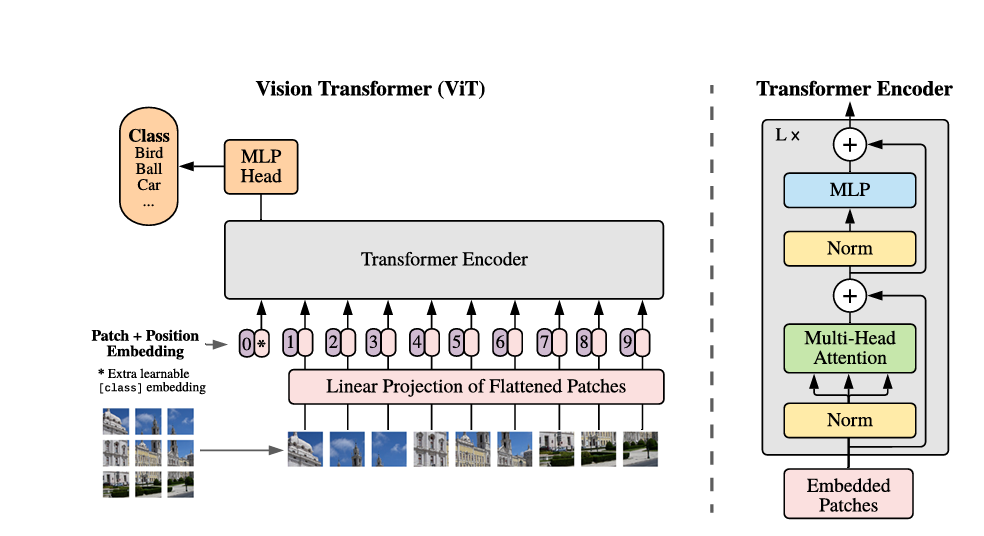
图1 模型的导览图
给定一张输入图像,首先将其划分为若干个图像块(patch)。设图像尺寸为 $H \times W$,每个 patch 尺寸为 $P \times P$,则 patch 数量为:$$ N = HW/P^2 $$ .
将这些 patch 展平并加上位置编码后形成一个长度为 $N$ 的序列。每个 patch 通过 patch embedding(一个全连接层)映射为一个特征向量。为了进行分类,借鉴 BERT 的做法,在序列起始位置(位置 0)添加一个可学习的特殊标记 [CLS]。该标记在自注意力机制中会与其他所有 patch 的特征相互学习,因此只需取 [CLS] 对应的输出作为全局图像表征,送入分类头即可完成分类。
Transformer encoder 的结构保持标准设计:层归一化 → 多头自注意力 → 残差连接 → 层归一化 → MLP → 残差连接。
下面推导全过程的向量维度(用字母表示):
输入图像尺寸:$H \times W \times C$($C$ 为通道数,通常为 3)。
每个 patch 展平后维度:$P^2 C$。
patch 数量:$N = \dfrac{HW}{P^2}$。
通过 patch embedding(输出维度 $D$),每个 patch 变为 $D$ 维,得到序列形状 $N \times D$。
添加 [CLS] token(也是 $D$ 维),序列长度变为 $N+1$,形状 $(N+1) \times D$。
加入位置编码(与序列相加,形状不变):仍是 $(N+1) \times D$。
Transformer encoder(多层,每层保持维度不变):输出 $(N+1) \times D$。
取出 [CLS] 对应的输出:$D$ 维向量。
最后通过分类头(线性层,输出类别数 $K$):得到 $K$ 维 logits。
归纳偏置
vit虽然做了如此处理,但在二维空间上的归纳偏置,仍旧是不如CNN卷积神经网络。transformer依旧还是得让每个图片学习自己与全局的关系。
混合神经网络
结合transformer的全局性和CNN卷积神经网络的归纳偏置,作者提出了一种混合神经网络:
不把大图片打成patch,直接让大图片过很多次CNN,然后将14*14的特征进行transformer的操作。这个设想也为将来埋下了伏笔。
大图片的微调
如果图片变大,还用16*16的分割方式,很显然你每个小patch会变大,破坏了原来的结构,这样会使得提前训练好的位置编码没用了。作者提出,这里只需要简单的做一个2D插值,这步操作就用torch自带的interpolate函数就能完成。这里的差值,只能是一个临时的解决方案,因为如果差值过大,精度会受到较大影响。
数据集的影响
由于上述提到的问题,当数据集不同(逐渐变大)时,ViT的训练效果和Resnet的效果到底谁好呢?
如图2所示:
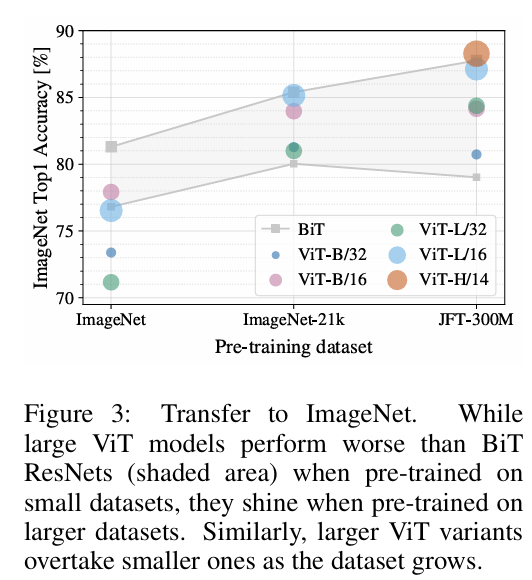
图2 不同数据集中,ViT和Resnet的测试结果
当数据集过小时,ViT是全面不如残差网络的,因为transformer没有用那些先验知识和归纳偏置,所以它需要更多的数据;用中间一档的数据集进行训练时,发现两者的效果差不多了;当用特别大的数据集训练时,ViT才能全面超越残差神经网络。
为了考虑到dropout等因素的影响,作者还做了大量消融实验,结果都能说明上述结论。
同时,论文中的一些数据展示,训练ViT的成本是比残差神经网络要低的。
关于混合模型,论文中提到,中小型数据集中比两者更好,但庞大的数据集效果会接近于Transformer自己,残差神经网络并没有起到一定的助力作用。
消融实验
ViT论文附录D.3至D.4对分类头类型和位置编码进行了消融实验。
关于分类头(D.3),ViT默认使用[CLS] token加小MLP(单隐层,tanh非线性)。最初尝试对patch embedding做全局平均池化(GAP)再接线性分类器效果很差,但进一步实验发现差异完全来源于学习率不同:
调整学习率后,GAP与[CLS] token表现相当。因此两者本质上没有优劣之分,只是需要不同的学习率。
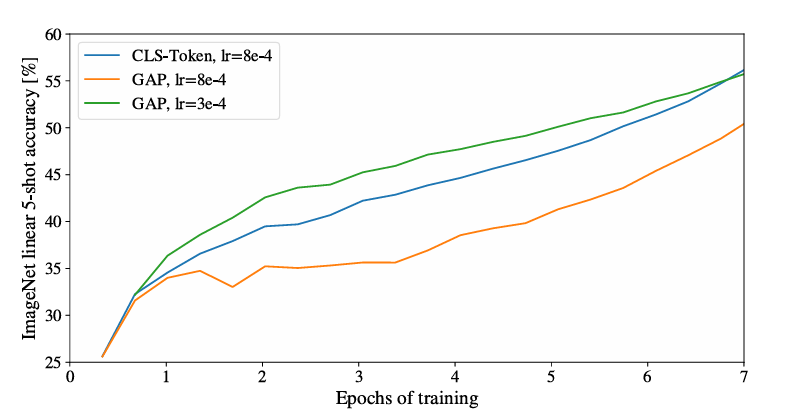
图3 不同分类头对准确率的影响
关于位置编码(D.4),对比了四种策略:无位置编码(视为patch集合)、1D可学习编码(默认)、2D可学习编码(分别学习X和Y方向各D/2维,再拼接)、相对位置编码(基于patch间偏移量的注意力偏置)。结果如表1所示:
无位置编码效果最差,而1D、2D、相对位置编码三者性能非常接近。此外,还尝试在不同层添加位置编码(仅输入层、每层、每层共享参数),差异也不大。这进一步印证了位置编码的主要作用是打破置换不变性,具体形式对最终性能影响很小。
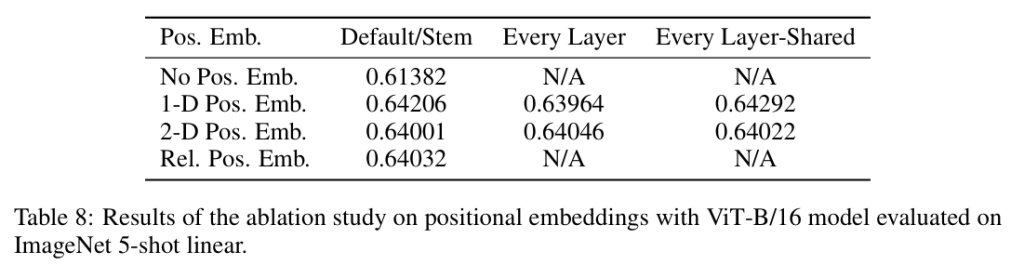
表1 四种位置编码对于准确率的对比
未来的工作
这篇论文提出了用transformer做CV的新视角,将来在做图像分类的基础上,研究者们还会研究如何去做图像的分割和检测。
👍